
The Governance Gap in Prior Authorization AI
Update, March 4 2026: A subject matter expert reviewed this article and flagged several technical inaccuracies in my description of the Da Vinci four-IG stack. I’ve corrected them. The core argument is unchanged; the Da Vinci mechanics are now more accurate. I’m grateful for the engagement.
The PA AI field has two separate problems. It has named one of them, funded solutions to it, and produced benchmarks for it. The other barely has a name yet.
Problem 1: Data connectivity. Getting structured FHIR data from provider EHRs to payer systems. Extracting clinically relevant information from the 80% of clinical records that exist only as unstructured free text. Routing transactions to 900+ payers with incompatible systems, 65% of which still process PA by phone, fax, or portal. The Da Vinci four-IG stack, multi-agent pipelines, MCP-connected FHIR datastores, NLP extractors — real infrastructure solving a real problem. Availity reports 80% touchless PA processing. Cohere reports 90%.
Problem 2: Governed criteria. Even when an AI agent has the right patient data and can reach the right payer endpoint, it has no authoritative, versioned mechanism to consume the rules that govern the decision. Payer coverage criteria exist as PDFs. Every AI PA vendor maintains a proprietary, manually-updated copy. When a denial is audited, nobody can reliably answer: “Which version of which rule was the agent following on that date?”
Problem 1 is being solved. Problem 2 is not.
The automation numbers above measure Problem 1. They tell you how often the agent reached the payer and submitted a decision. They say nothing about whether the decision was governed. Faster automation of an ungoverned system doesn’t close the governance gap — it scales it.
The Da Vinci Stack: What It Solves and Where It Stops
With 900+ payers operating different systems, different criteria formats, and different exchange mechanisms, the only way AI PA agents can function reliably across the ecosystem is if everyone is working from the same interoperability standard. That’s what Da Vinci is. Not a vendor framework — a set of HL7 implementation guides that define how PA should move between provider and payer systems, in a format that works the same way regardless of which payer, which EHR, which platform. The patient benefits because the process doesn’t break at every system boundary. When I describe a Da Vinci-aligned agentic architecture, I mean a system built on those IGs — designed for the interoperability reality of 900+ payers, not optimized for one.
The four-IG stack is the current reference standard. It’s worth being specific about what each piece does and doesn’t do.
CRD (Coverage Requirements Discovery) fires a CDS Hooks call at order entry. The EHR asks: is PA required for this service, for this payer, for this plan? If yes: what documentation is needed? CRD returns the answer in real time, before the clinician leaves the encounter. This is meaningful progress over portal lookups. CRD is not required to touch criteria evaluation, but it is permitted to — and for simple cases, the intended direction is that CRD will determine criteria have been met and return the auth number directly, without requiring the full DTR workflow.
DTR (Documentation Templates and Rules) delivers a questionnaire to the EHR — one that may include embedded CQL for flow-control and pre-population logic; some forms will have neither. In principle, that CQL executes against the patient’s FHIR record to auto-populate questionnaire responses. In practice, most EHRs don’t seem interested in implementing a CQL engine. Instead, they may plan to use AI against the CQL to determine if and how to pre-populate the form — an approach CRD 2.2.0 is accommodating by relaxing the specification language. Where pre-population falls short — which covers most clinically relevant information — the questionnaire surfaces gaps for the clinician to fill.
DTR, like CRD, can also be used to trigger criteria evaluation directly. When using adaptive forms, the final exchange from a payer can be a coverage-information response that includes authorization — no separate PAS submission required for those cases.
This is where the current architecture gets closest to machine-executable criteria. CQL is the right approach where it exists: deterministic, executable against structured data, authorable by payers, version-controlled. But not all payer logic is exposed via CQL. Flow-control logic can be hidden behind DTR’s adaptive form interface, where payers ask new questions based on previous answers and the rules governing what’s solicited aren’t visible — and in principle could be a facade over an AI making decisions on the fly. The limitation is both adoption and coverage. Most payers haven’t yet authored their criteria in CQL. And even where CQL exists, 80% of clinically relevant information lives in free-text notes — prior treatment failures, diagnostic findings, clinical reasoning — that CQL can’t query.
CDex (Clinical Data Exchange) handles Task-based requests for additional clinical documentation. It’s designed for three specific situations: a human reviewer determines additional data is needed that couldn’t be identified up front; solicited attachments are incomplete or incorrect; or the EHR has data available but has chosen not to expose it to the payer without a human in the loop — patient consent and minimum-necessary rules apply. If the questionnaire requires evidence that the patient failed six weeks of conservative therapy and that fact lives in a physician’s note, CDex is how the agent requests it. It gets the document. It doesn’t evaluate what’s in it.
PAS (Prior Authorization Support) receives the completed FHIR Claim with DTR questionnaire responses attached and routes it to the payer: FHIR API for CMS-0057-F-compliant payers, X12 clearinghouse for legacy systems. Returns the ClaimResponse to the EHR.
The Da Vinci stack solves the protocol and transport problem. It establishes how PA requests move between EHR and payer in a structured, computable format. CQL/DTR is the right direction for machine-executable criteria, and payer adoption will continue to grow. What Da Vinci doesn’t address — and isn’t designed to — is the implementation-layer question of which versioned criteria each agent is operating under before any of that protocol executes. That’s deliberately outside the scope of a transport standard. It’s the implementer’s problem to solve.
The Agentic Execution Layer
The following table is an example of how one might create a multi-agent PA architecture that maps to the Da Vinci Implementation Guides which would include six agents:
| Agent | Da Vinci alignment | Function |
|---|---|---|
| PA Orchestrator | CRD | Determines PA requirement, routes workflow, manages state |
| Eligibility & Coverage | CRD + CDex | Member eligibility, coverage tier, applicable formulary |
| Clinical Data | DTR + CDex | CQL or AI-based pre-population, NLP on unstructured notes, CDex requests |
| Policy Evaluation | DTR | Maps evidence against payer criteria, generates recommendation |
| PA Submission | PAS | Builds FHIR Claim, routes to payer, handles ClaimResponse |
| Status & Monitoring | PAS (post-submission) | Tracks pends, timelines, escalations |
The Policy Evaluation Agent is where the governance gap is most acute. This is the agent that answers: “Does this request meet criteria?” It receives the assembled clinical evidence package and evaluates it against the applicable payer coverage criteria for this service type, this plan, this date of service.
To do this correctly, the agent needs an authoritative, versioned source for those criteria. What it currently has, across most production implementations, is whatever its developers loaded into it — usually a proprietary interpretation of payer PDF documents, last manually updated some weeks ago.
Three Approaches to Criteria. Three Failure Modes.
Approach A: Proprietary policy digitization is the dominant pattern. Most PA AI vendors ingest payer policy PDFs and maintain an internal criteria database. The Policy Evaluation Agent evaluates against that database.
The failure modes are well-documented. Payers update coverage criteria quarterly or ad hoc — no push notification exists for vendors running proprietary copies. AMA 2025 data: 30% of physicians report PA requirement data in their system is rarely or never accurate. And when a denial is audited — by CMS, by a state regulator, by a patient’s legal team — the vendor faces a question no proprietary copy can reliably answer: was the version of the criteria in your system on that date the same version the payer had in effect?
Approach B: CQL via Da Vinci DTR is the right architectural direction. CQL is deterministic. Criteria authored in CQL and published through DTR are versioned by definition. The payer owns the rule set and can update it. This is what machine-executable coverage criteria should look like.
The current limitations are adoption gaps, not architectural gaps. Most payers haven’t finished authoring their criteria in CQL. And even where CQL questionnaires are complete, they handle deterministic rule evaluation well and fail on temporal clinical reasoning (“patient must have documented failure of 6 weeks of conservative therapy”) and on the unstructured data that constitutes most of the clinical record. CQL asks structured questions against structured FHIR data. It doesn’t extract a treatment failure from a physician’s note.
Approach C: LLM against policy documents is emerging as a fallback for the gap left by approaches A and B. Prompt the model with the payer criteria document and the patient record; ask for a coverage determination.
MedCity News characterized the audit risk as “unacceptable” in early 2026. The core problem isn’t model accuracy — it’s that an LLM applied to an unstructured document cannot produce a deterministic audit trail. You can’t point to the specific rule that generated the recommendation, because the recommendation wasn’t produced by rule evaluation. Texas, Arizona, and Maryland have passed legislation requiring human review for AI adverse determinations — not because legislatures distrust AI, but because a probabilistic output can’t satisfy the audit requirement that adverse determination oversight demands.
The shared failure across all three approaches: none produces a versioned, auditable, authoritative criteria record tied to each decision. The Policy Evaluation Agent in all three cases is evaluating against something, but not against something it can name, version-pin, and log alongside each recommendation.
The Regulatory Pressure That Makes This a Now Problem
This would be a slow-burn problem if the regulatory environment weren’t accelerating directly toward the question the governance gap can’t answer.
CMS-0057-F requires Prior Authorization APIs in production by January 1, 2027. Denial reasons must cite specific policy provisions — not “clinical criteria not met” but which criteria, applied to which evidence. Public reporting of PA metrics begins March 31, 2026: denial rates, approval rates, and turnaround times become visible to regulators and the public. This is the first time PA aggregate behavior is systematically visible outside the health plan.
The CMS WISeR Model launched January 2026 as a federal pilot of AI-assisted PA across Medicare in six states. AI-supported decisions are under direct federal monitoring through 2031. WISeR is, among other things, generating decision-level evidence on AI PA behavior — the first federal dataset of this kind. The audit methodology that emerges from WISeR will define what “demonstrably governed” means for the rest of the industry.
State AI legislation in Texas, Arizona, and Maryland prohibits AI from being the sole basis for an adverse determination. Human review is required for denials. This creates an audit requirement at every adverse decision: what did the AI recommend, on what basis, and what did the human reviewer conclude? A system that can’t answer the first two parts of that question can’t satisfy the human oversight requirement in any meaningful way.
CHAI-PA-TRANS-003 — Context Version Auditability — is the requirement from the Coalition for Health AI’s Testing & Evaluation Framework that it be possible to determine exactly which governance context an AI agent was operating under at the time of any specific decision. It is a named compliance requirement from a framework developed by 100+ experts across UnitedHealth, CVS Health, Blue Cross Blue Shield, Mayo Clinic, Stanford, and others. Most current PA systems cannot satisfy it, because they have no mechanism for recording which criteria version the agent was running when a specific recommendation was generated.
SCS: Context Managed as an Asset
Structured Context Specification (SCS, open source) is not a replacement for FHIR, CQL, or MCP. It’s the layer those protocols don’t include. It provides the ability to define context as a versioned, immutable asset that can be managed at either dev-time or run-time.
Supervisory Control Plane (SCP, commercial offering) stores, distributes and monitors AI services and the context they are using at a particular time (to paraphrase, ‘the right context for the right agent at the right time’). It also adds a real time governance and compliance reporting capability.
The Da Vinci architecture provides protocol and transport (FHIR, X12), tool connectivity (MCP), CQL-defined criteria where payer adoption exists (DTR), and clinical data exchange (CDex). What it deliberately doesn’t address — because it’s a protocol standard, not an implementation framework — is the question of which versioned criteria each agent is operating under before the protocol executes. That’s the implementer’s layer. And across most production PA implementations today, that layer has no governed, authoritative, structurally enforced answer. Not a prompt. Not a guardrail. A declared artifact, sourced from a registry, that tells each agent what it is, what it’s authorized to do, which version of which standards it’s operating under, and how to treat the runtime inputs it receives.
SCS Workflow:
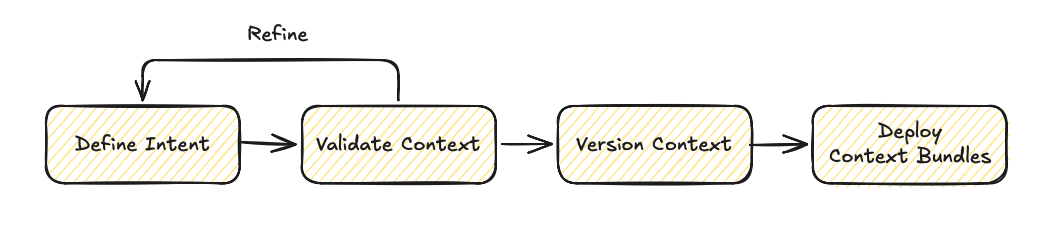
SCP Workflow:
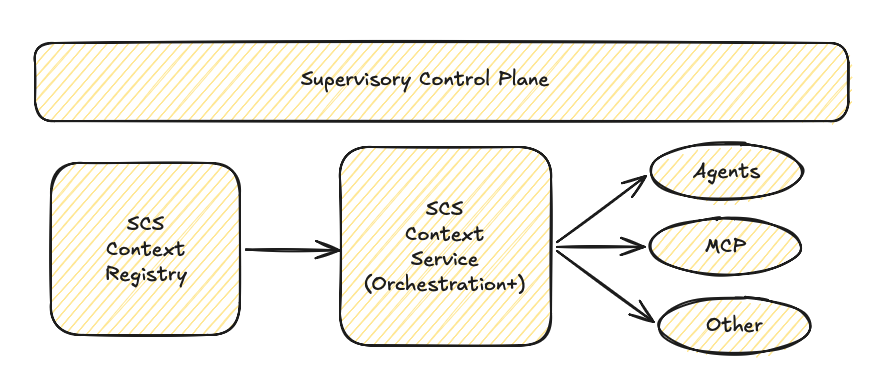
All context and agents are registered in the registry and context is streamed as needed, on demand.
Each agent receives its authorized bundle before the patient record loads, before the payer response arrives, before any runtime input enters the pipeline.
What SCS provides to each agent:
Versioned, authoritative criteria. The Policy Evaluation Agent isn’t evaluating against “our criteria database.” It’s evaluating against payer-criteria-[payer]-v4.2, imported from a registry, version-logged at initialization. When the same agent processes a denial six months later and the decision is audited, the log shows exactly which bundle version was in effect.
Trust hierarchy. The SCS bundle is authoritative. FHIR patient data, NLP-extracted clinical facts, and payer responses are informational. Runtime input cannot override the authoritative layer. A PA agent that processes clinical notes, member data, and payer responses alongside loosely defined rules has no structural mechanism to distinguish governing criteria from content it’s processing. SCS establishes that boundary before the first token arrives.
Scope isolation. Each agent has a declared, documented scope. The Policy Evaluation Agent recommends — it doesn’t deny autonomously. The Submission Agent submits authorized requests — it doesn’t expand scope based on runtime input. This makes excessive agency structural rather than behavioral: the agent doesn’t have undefined capabilities that a malformed payer response could trigger; it has defined capabilities that governance context enforces.
Escalation triggers. Structural definitions of what routes to human review vs. what proceeds autonomously. Ambiguous cases, criteria not clearly met, requests outside authorized scope — all escalate by definition rather than by model training.
The bundle composition for a PA workflow:
bundle: pa-workflow-governedversion: "1.0.0"imports: - bundle: ncpdp-pa-standards-2026-q1 - bundle: payer-criteria-[payer]-v4.2 - bundle: chai-clinical-ai-guidelines-1.0 - bundle: scs-security-baseline-1.0Each source is independently versioned. When NCPDP releases a Q2 standards update, you update that bundle. The payer criteria update is separate. CHAI guidelines update independently. Agents consuming the composed bundle get each source at its correct version — with a full audit trail of which version was in effect at each decision.
What this closes:
CHAI-PA-TRANS-003 is satisfied. Every decision is logged with the bundle version in effect at the time — not a claim that the agent was following policy X, but a record of which version it was running.
Criteria currency is no longer a manual update problem. Update the bundle, agents update. The 30–90 day lag in proprietary policy copy maintenance becomes a version release, managed like a software dependency.
Composability is structural: NCPDP workflow rules, payer criteria, CHAI guidelines, and the security baseline compose into one governed bundle. Each source remains independently authored and versioned — they arrive at the agent together.
Injection defense is structural rather than behavioral. A PA pipeline processing member data, clinical notes, and payer responses is a high-value target. The trust hierarchy means runtime inputs are informational by definition; they cannot shift agent behavior regardless of what they contain. (The mechanisms are detailed in the security baseline — importable directly into any PA bundle.)
What SCS doesn’t fix: the unstructured data extraction problem is real and remains. SCS governs the context agents operate under — it doesn’t improve NLP extraction from free-text clinical notes. The CQL adoption gap at payers doesn’t close because governance context exists. SCS closes the governed criteria problem; the data connectivity problem is what the Da Vinci stack is already addressing.
Proof of concept. I transposed the full CHAI T&E Framework v1.0 for prior authorization into SCS — 4 documents, 15 requirements with measurable benchmarks across CHAI’s four principles: usefulness, fairness, safety, and transparency. PPV parity across demographic subgroups. Scope boundary enforcement with a 95% accuracy threshold. Decision traceability. Demographic disparity monitoring across auto-approved vs. manually reviewed pathways. The framework runs to dozens of pages of expert prose. The SCS transposition is 24KB — not because it’s a summary, but because structured data is more compact than the explanatory context humans need around it. The CHAI bundle is in the repository and importable today.
SCP: From Governed Context to Measured Effectiveness
Governing individual agents with SCS answers the auditability question. It doesn’t answer the effectiveness question: is the AI PA service producing the right outcomes, and how do you improve it?
The Supervisory Control Plane (SCP) is the natural next layer. Where SCS governs individual agent sessions, SCP governs the fleet and generates the evidence that the governance is producing outcomes.
SCP adds bundle version management across the agent fleet — no agent runs an unauthorized bundle version. When NCPDP releases a Q2 update, SCP controls the rollout: which agents get the update, when, in what sequence. In a fleet processing hundreds of thousands of daily PA transactions, unauthorized bundle versions are a compliance exposure. SCP makes version drift visible rather than silent.
The core capability is outcome correlation. SCP attributes outcomes to bundle versions:
| Metric | What SCP tracks |
|---|---|
| Approval rate by bundle version | Did the criteria update change approval rates for this service type? |
| Denial rate trend | Is the trend moving in the expected direction as criteria evolve? |
| Appeal outcomes | When denied decisions are overturned on appeal, were the agents running the correct version? |
| Time-to-decision | Does governed context correlate with faster or slower decisions? |
| Human review overturn rate | When agents escalate, what % of human reviews reverse the recommendation? This measures criteria quality, not just agent behavior. |
Because SCS bundles are versioned, SCP can roll out test context (canary test), measure effectiveness and then either refine or roll back instantaneously.
The effectiveness loop:

This is the answer to the question regulators, payers, and health system partners will ask as federal monitoring of AI PA intensifies: “How do you know your AI service is producing the right outcomes — and how do you improve it?” With SCP, the answer is evidence rather than attestation. Version X produced these outcomes. Version Y changed them by this amount. Human review of version X’s recommendations was overturned at this rate, which means the criteria need refinement in these specific areas.
The Architecture, Complete
The Da Vinci stack is the right foundation. It solves the protocol and transport problem that was the first obstacle to automated PA at scale. CQL/DTR is the right direction for machine-executable criteria, and payer adoption will continue to grow. None of this is in dispute.
What the current architecture is missing is a governance context layer: a versioned, authoritative artifact that travels with each agent before any session begins, establishes a trust hierarchy between authoritative criteria and runtime inputs, and produces a decision-level audit record that satisfies CMS-0057-F denial reason requirements, answers CHAI-PA-TRANS-003, and meets state adverse determination oversight demands.
| Without governed context | With SCS + SCP | |
|---|---|---|
| Criteria version at decision | Unknown or unverifiable | Pinned, logged, auditable |
| Criteria update propagation | Manual, 30–90 day lag | Bundle release, fleet-managed |
| Audit response | ”We believe the agent was following policy X" | "The agent was running bundle v4.2 — here is the record” |
| Effectiveness measurement | Aggregate approval/denial rates | Outcome attribution by bundle version |
| Regulatory evidence | Attestation | Evidence package |
The governance layer is not a future requirement. CHAI-PA-TRANS-003 names it. CMS-0057-F is creating the public accountability structure that makes the gap visible. WISeR is generating the federal dataset that will define what “governed” means for AI PA through 2031.
The CHAI bundle, the security baseline, and the full SCS specification are in the repository. If you’re building a PA pipeline and the governance layer is the gap — start there.